
Introduction
There are different modes of MPI send: MPI_Send, MPI_Isend, MPI_Ssend, MPI_Bsend, and so on. They can be local or non-local, blocking or non-blocking, and synchronous or asynchronous. Their definition and differences are explained here in detail.
MPI_Send
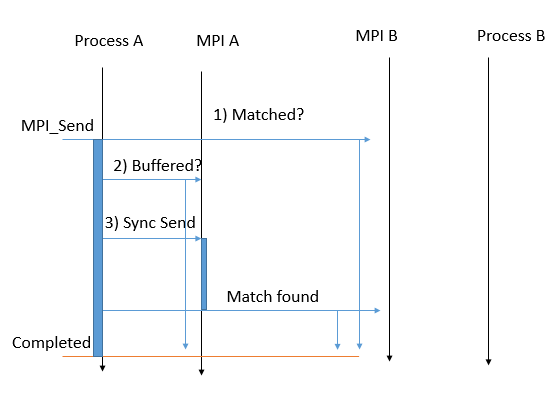
This is the standard mode. When it is called, (1) the message can be directly passed to the receive buffer, (2) the data is buffered (in temporary memory in the MPI implementation) or (3) the function waits for a receiving process to appear. See the picture below. Therefore, It can return quickly (1)(2) or block the process for a while (3). MPI decides which scenario is the best in terms of performance, memory, and so on. In any case, the data can be safely modified after the function returns.
MPI_Ssend
It is the synchronized blocking function. When this function returns, the destination has started receiving the message. The moment the destination starts receiving, it signals an ACK to the source.
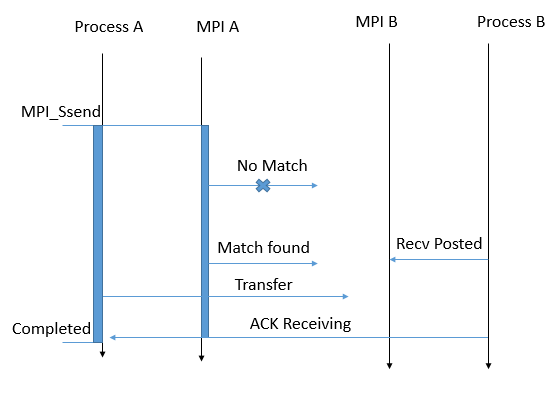
Note, the signal of receiving the message is the difference between MPI_Ssend and MPI_Send.
MPI_Bsend
It is the local blocking send. The programmer defines a local buffer when this function is called. If there is not a matching receive available, the process is blocked until the message is copied into the buffer. Therefore, the programmer can immediately modify the source data after the function returns.
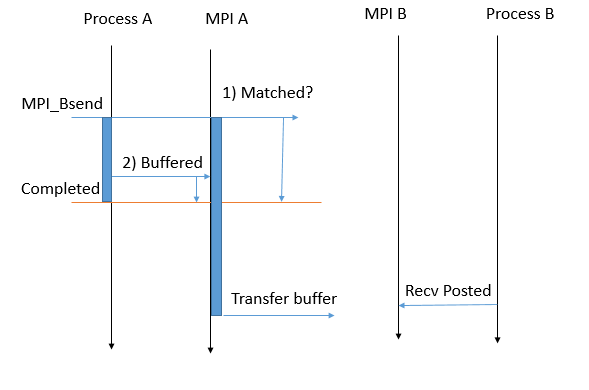
Note, when the function returns the message is probably not sent yet, it will happen concurrently in the background of the process when a matched receive is found.
MPI_Rsend
It is a blocking function the same as MPI_Send, but, it expects a ready destination to receive the message. This can increase the MPI performance if the programmer is sure there is a receive function waiting for this. If no receive posted before, it is erroneous.
MPI_Isend
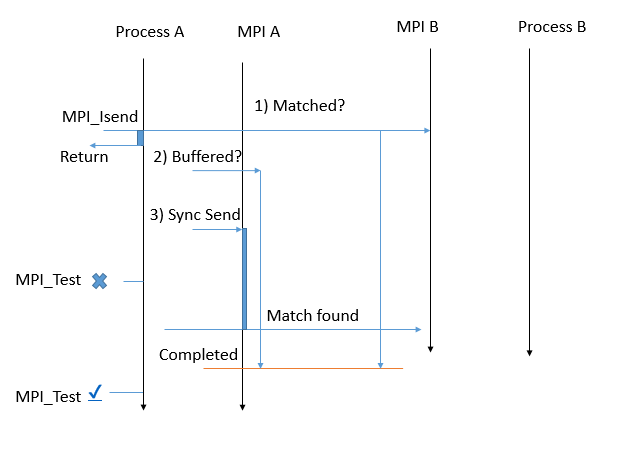
It is the non-blocking version of MPI_Send. When this function is called the function returns immediately but runs MPI_Send actions in the background of the process. Therefore, After the function returns, the data must not be modified unless MPI_Test and MPI_Wait confirm MPI_Isend is completed. After the completion, the data is reusable because it either is buffered in MPI or sent to the destination.
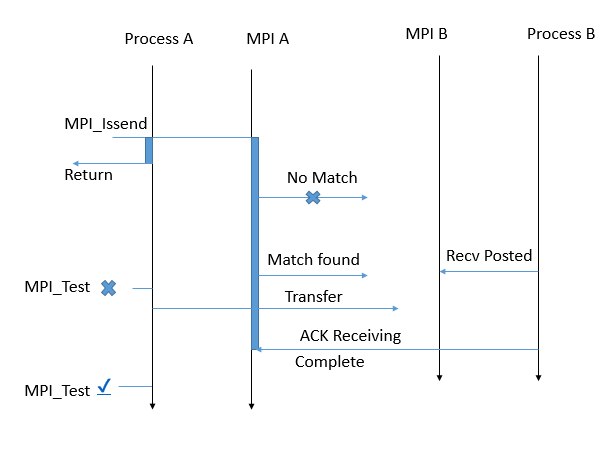
MPI_Issend
It is the non-blocking version of MPI_Ssend. It returns immediately, but runs MPI_Ssend actions in the background. MPI_Test or MPI_Wait must be used to assess if the function is completed in the background. At that point, not only the message has been sent but also the destination has started to receive the message.
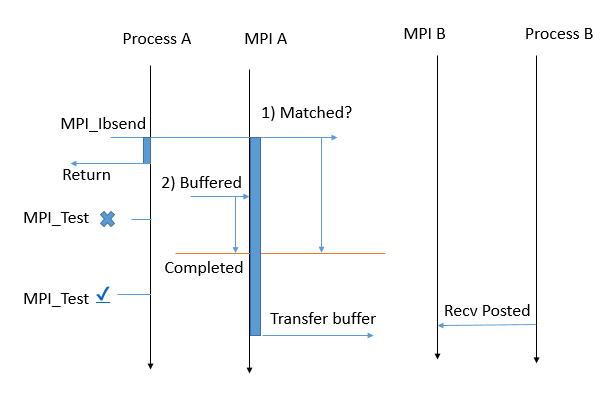
MPI_Ibsend
This is the local non-blocking send. It blocks for neither copying the message to the buffer nor sending the message. After the test positive or wait, we can modify the source data because, if it is not sent, it is locally copied to the allocated buffer.
MPI_Irsend
The same as MPI_Rsend, but non-blocking.
Priority list
It’s hard to give a recipe for all the problems. However, some points can help to choose the right mode:
- When there is a deadlock, non-blocking communication can help.
- When there is a race condition, blocking communication can help.
- When there is a computationally expensive task, a non-blocking communication, posted before the task, may improve the performance.
MPI_SendandMPI_Isend, are top in the priority list as MPI decides what is best.MPI_SsendandMPI_Issend, when the sender needs to know when the message is received and to avoid local buffering.MPI_Ssendcan be useful for debugging.MPI_Bsend,MPI_Ibsend,MPI_Rsend,MPI_Irsendare for fine-tuning the performance.
More like this
If you are interested in debugging an MPI code with VS code, see my post here.
References
I got ideas and codes from the below website(s)
MPI 3.1 Report - section 3.4, 3.7
Latest Posts
Comments
7 comments
Behzad
16-Feb-2022
Thank you dear Sorush. This post helped me a lot.
Hamed
13-Mar-2022
Thank you. It was a great help.
yael
2-Mar-2023
thank you this helped
Xiang Li
4-Feb-2024
Thank you. Your figures are crystal clear and worth thousands of words.
Vishnu Monn
1-Sep-2024
Hi Sorush. Thank you very much for this article. The sequence diagrams provide a good visualisation to understand better the different MPI send methods.
Fabian
20-Jul-2024
Very nice post
sheng
7-Nov-2024
The diagram for buffered is a little confusing.
Could you please make it clearer?